CloudFront + S3 Delivery
The static website (HTML, CSS, JavaScript) is hosted in a private S3 bucket and delivered through CloudFront. CloudFront serves as the only access point — the S3 bucket has no public access. S3 versioning is enabled on the bucket — files are encrypted at rest with SSE-AES256.
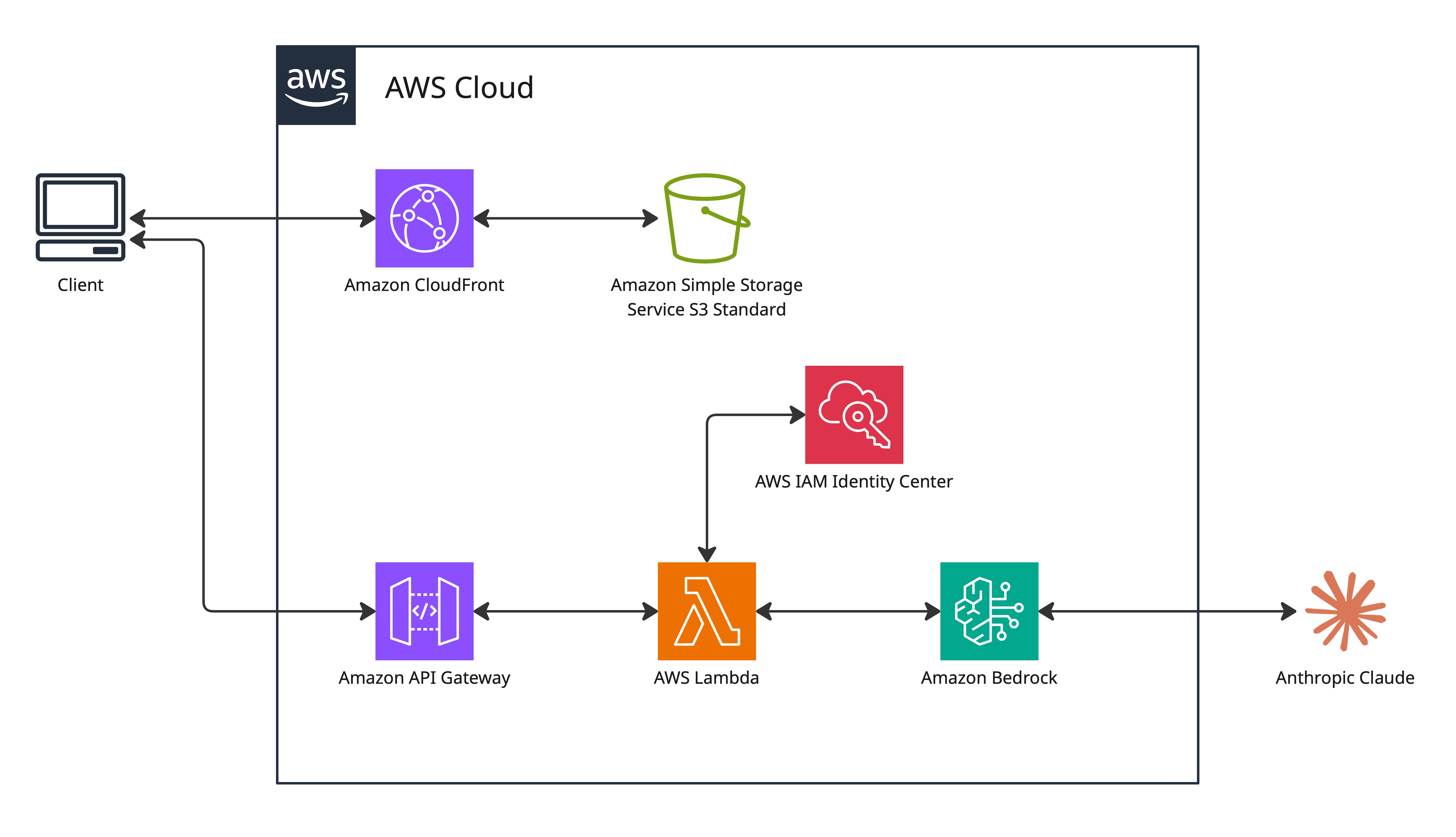
CloudFront provides two key benefits beyond CDN caching:
- HTTPS enforcement. My CloudFront distribution redirects HTTP to HTTPS. HTTPS is required for browsers to allow camera access — browsers restrict camera APIs to secure contexts only.
- Cost control. S3 charges for data transfer out. CloudFront caches at edge locations so subsequent requests are served from cache, not from S3.
Origin Access Control (OAC)
Origin Access Control (OAC) is the mechanism that ties the CloudFront distribution to the S3 bucket. CloudFront uses OAC to sign requests to S3, and the bucket policy requires that signature.
# S3 bucket policy (simplified)
{
"Principal": {
"Service": "cloudfront.amazonaws.com"
},
"Condition": {
"StringEquals": {
"AWS:SourceArn": "arn:aws:cloudfront::ACCOUNT:distribution/DIST_ID"
}
}
}
The condition scopes access to this specific distribution ARN — not all CloudFront distributions in the account, and also not the CloudFront service generally. Even if someone created another CloudFront distribution pointing at this bucket, the bucket policy would reject requests from it.
CORS Configuration
The frontend (served from CloudFront's domain) makes API calls to API Gateway (a different domain). Browsers enforce the same-origin policy and block these cross-origin requests by default. CORS headers on the API Gateway response explicitly allow them.
Access-Control-Allow-Origin: * Access-Control-Allow-Methods: POST, OPTIONS Access-Control-Allow-Headers: Content-Type
Access-Control-Allow-Origin: * means any domain can make
browser-based requests to the API — not just the portfolio site. Combined with
the fact that the API endpoint URL is visible in the page's JavaScript source,
there is no practical barrier to another site calling this API. This was a
learning gap, and only something I realised after deploying this web application. If I decided to rebuild this, the origin would be restricted to the specific
CloudFront domain. Other methods of securing access would be to utilise API keys so that only authenticated requests can reach the Lambda function.
Lambda Configuration
| Setting | Value | Reason |
|---|---|---|
| Runtime | Node.js 18.x | AWS SDK v3 (@aws-sdk/client-bedrock-runtime) |
| Memory | 512 MB | Handles base64 image encoding in memory |
| Timeout | 30 seconds | Accommodates Bedrock model inference latency |
| Architecture | x86_64 | Default — arm64 would be cheaper but negligible at this scale |
The 30-second timeout is driven by Bedrock response latency. Claude 3.5 Sonnet processing a high-resolution image with a detailed extraction prompt takes 4–12 seconds in practice. The timeout provides headroom for occasional slower responses without failing the user request.
Memory at 512 MB handles base64 encoding of a typical phone camera image (3–8 MB JPEG → ~4–11 MB base64) in memory. CloudWatch logs confirm actual usage is well below 512 MB. If I had hundreds, or thousands of actual Lambda invocations, I would be able to optimise the memory (and therefore compute) from the log data I collect. There is a tool called "aws-lambda-power-tuning" which is open source software that allows me to optimise my lambda function for cost.
API Gateway
A single API Gateway resource handles the puzzle scan endpoint:
POST /scan-sudoku. The request body contains a base64-encoded image
and is passed directly to the Lambda function as the event payload.
API Gateway handles SSL termination, request routing, and throttling. As noted in the CORS section, access security on this API was not implemented correctly. The endpoint has no API key, no authorizer, and no usage plan — any caller with the URL can trigger the Lambda, which calls Bedrock and incurs a charge. IAM correctly scopes what Lambda is permitted to do, but IAM doesn't control who is allowed to trigger Lambda in the first place. If rebuilding this, the right approach would be to utilise an API Gateway usage plan with a per-key rate limit to cap costs. The default throttle limits (10,000 req/s) are far too high to act as a meaningful guardrail.
Network Design
Lambda runs in AWS's managed environment with no VPC configuration. The workload calls public APIs (Bedrock) and accesses AWS-internal services (S3), neither of which requires VPC deployment.
Lambda accessing Bedrock routes over AWS's internal network. Lambda accessing S3 for (future) image storage would also route internally. No traffic to AWS services traverses the public internet.
The key question when evaluating VPC deployment is... does this workload need to access private network resources? For SUDOKOO, the answer is no. All resources are either AWS managed services (accessible internally) or public APIs (HTTPS).
Bedrock Integration
Amazon Bedrock provides managed access to foundation AI models without infrastructure management. The Lambda function calls the Bedrock API with the image data and a prompt for obtaining a structured puzzle data response.
// Lambda handler (simplified)
const { BedrockRuntimeClient, InvokeModelCommand } = require('@aws-sdk/client-bedrock-runtime');
const client = new BedrockRuntimeClient({ region: 'us-east-1' });
const response = await client.send(new InvokeModelCommand({
modelId: 'anthropic.claude-3-5-sonnet-20241022-v2:0',
contentType: 'application/json',
accept: 'application/json',
body: JSON.stringify({
anthropic_version: 'bedrock-2023-05-31',
max_tokens: 2000,
messages: [{
role: 'user',
content: [
{
type: 'text',
text: 'Extract the 9x9 Sudoku grid...'
},
{
type: 'image',
source: {
type: 'base64',
media_type: 'image/jpeg',
data: base64Image
}
}
]
}]
})
}));
Claude is asked to return JSON only. The Lambda code also strips markdown "wrapper" as a fallback if Claude wraps the response. After extraction and puzzle validation, the Lambda runs its own backtracking solver and returns both the puzzle and solution to the frontend. Claude handles extraction; Lambda handles solving; the browser handles gameplay and validates each move against the stored solution in real time.
Failure Modes
The AI extraction has two main failure modes, observed through CloudWatch logs by comparing response output with the original puzzle photos:
- Grid alignment errors. Correct digit values placed in adjacent cells — typically off by one row or column.
-
Character recognition errors. Digits misread — most commonly
1read as7, or6read as8.
The built-in puzzle validity checker (verifying no duplicate values in any row, column, or 3×3 box) catches alignment errors.
Overall success rate: approximately 50%. For a single-user personal tool, this is acceptable. Re-scanning with better lighting or a different angle usually resolves failures.
Future Improvements
- Structured JSON output. Claude now supports structured output mode, which guarantees a specific JSON schema in the response. The current implementation parses free-text output, adding complexity and fragility. Structured output would simplify the Lambda function significantly and improve reliability.
- CI/CD pipeline. Manual S3 upload + CloudFront invalidation per frontend change was the most operationally painful part of this project. A GitHub Actions workflow (push to main → S3 sync → invalidation) would take no time to implement and save significant time on all future iterations.
- Confidence threshold and retry. If Bedrock returns a response with validation errors, automatically retry with a prompt variation before returning failure to the user.
- Resource tagging. All resources should be tagged from day one for cost attribution and resource management.
IAM Design
The Lambda execution role has two permissions:
- AWSLambdaBasicExecutionRole — AWS managed policy, attached directly. Grants CloudWatch Logs write access across all log groups.
-
Custom inline policy —
bedrock:InvokeModelscoped to the specific model ARN:anthropic.claude-3-5-sonnet-20241022-v2:0. The function cannot invoke any other Bedrock model. Switching to a different model requires an explicit IAM update.
Encryption
| Data | In transit | At rest |
|---|---|---|
| Static website files | HTTPS via CloudFront (ACM cert) | SSE-S3 on bucket |
| Puzzle image (upload) | HTTPS via API Gateway | Not stored |
| Lambda ↔ Bedrock | TLS (AWS internal) | N/A |
| Lambda ↔ S3 | TLS (AWS internal) | SSE-S3 |
Uploaded images are not stored — they are processed in Lambda memory and discarded. No user data persists beyond the duration of the Lambda invocation. Saving the images would help me build up a training dataset for training custom ML models in the future (if I was to continue building this).
WAF Decision
AWS WAF was deployed initially with three managed rules: SQL injection protection, XSS protection, and the common ruleset (CRS). Cost: $8/month. It is a layer 7 (application layer) security feature, not deep infra security.
For a hobby project, a single-user portfolio project with no real traffic, no user accounts, no stored data, and no financial transactions, $8/month seemed expensive.
If this was a "real webapp" with actual traffic, authenticated users, stored PII, payment processing, I would reapply the WAF.
Cost Breakdown
| Service | Monthly cost | Notes |
|---|---|---|
| Lambda | ~$0 | Free tier — sporadic single-user usage |
| API Gateway | ~$0 | Free tier |
| S3 | ~$0.01 | Small static files, minimal requests |
| CloudFront | ~$0 | Free tier — 1 TB/month data transfer included |
| Bedrock (Claude 3.5 Sonnet) | Variable | ~$0.003–0.015 per scan depending on image size |
| CloudWatch Logs | ~$0 | Minimal volume |
| Total (excluding Bedrock) | ~$0/month | Bedrock is the only meaningful cost |
Bedrock pricing for Claude 3.5 Sonnet is based on input and output tokens. Estimated cost per scan was calculated using typical token usage and AWS published pricing. Actual costs can be observed in Cost Explorer at an aggregate level, but per-request cost requires custom logging of token usage.
Deployment Process
Infrastructure was initially set up through the AWS console. The goal was
building hands-on understanding of each service's configuration options visually. The
painful part was CloudFront cache invalidation — every frontend change required
triggering a /* invalidation and waiting 60–90 seconds for it to
propagate. Doing that manually on every iteration became tedious quickly. A proper CI/CD pipeline (push to main → S3
sync → invalidation) would eliminate the manual step entirely.