Serverless · Data Pipeline · APIs
AWS Stock Screener
Serverless stock screener and portfolio tracker with Telegram bot interface. Cost ~$0/month.
The Problem
I had developed a systematic trading strategy that I wanted to test with a paper trading account. I needed a daily ranked list of entry signals from a large stock watchlist, and a custom view of my active positions which was designed based on my exit strategy logic. No commercial software offered the right combination.
The solution needed to be cheap to run, have a visual dashboard, and flexible enough to evolve with the strategy.
What It Does
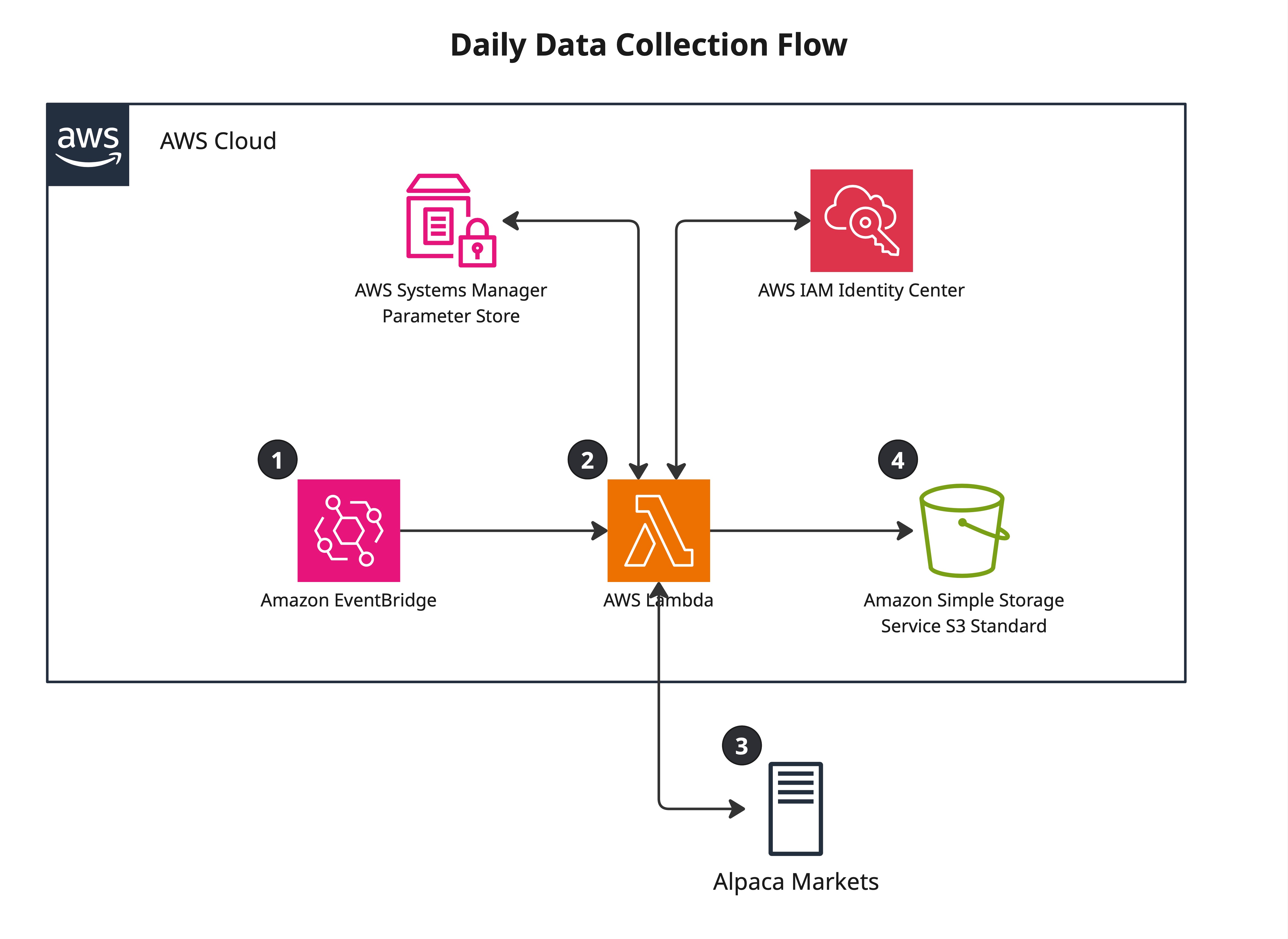
There are two main flows in this project. The first ingests end-of-day price data
each morning, computes the custom attributes required to generate entry signals, and
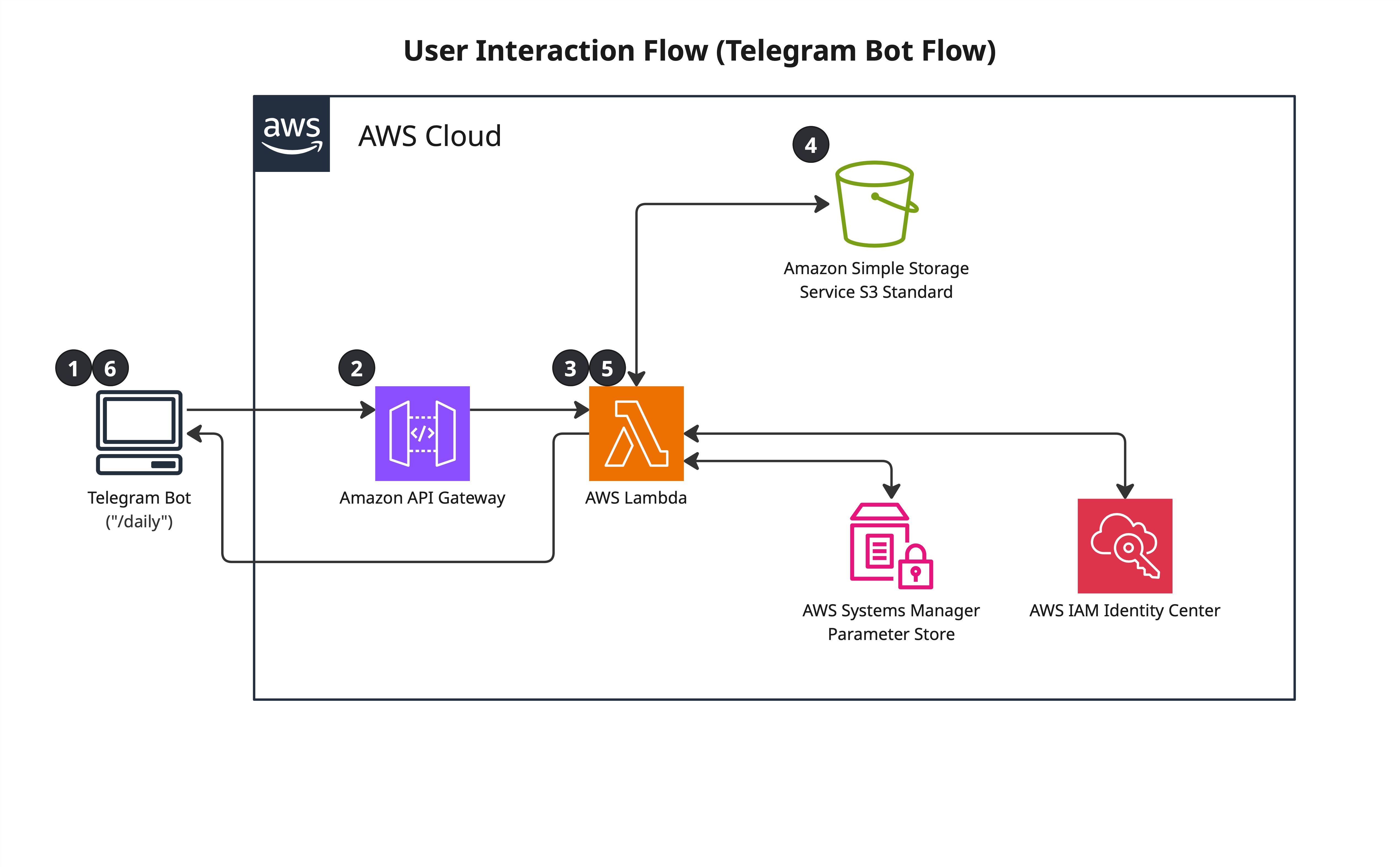
stores the results in S3. The second lets me query those results and view my active
positions through a custom lens tied to my exit logic — triggered by sending
/daily from Telegram, which fetches live position data from my broker
API and returns a formatted summary. The whole thing runs in under 2 minutes and
costs effectively nothing.
| Outcome |
|---|
| ~1,000 stocks screened and ranked daily before market open |
| Top candidates delivered to Telegram on demand |
| Replaced a slow, inconsistent manual workflow |
| Runs at ~$0–2/month (mostly within free tier) |
The Solution — Two Flows
Below is the diagrams for the flows.
Flow 1 — Daily Data Collection
Flow 2 — Telegram Bot Interface
Full data flow details and service configuration in the technical deep-dive →
Key Design Decisions
Decision · Compute
Lambda over EC2 or ECS. The workload runs once daily plus sporadic bot queries, which means I don't need consistently available compute resources. I would be paying for EC2 and not utilising its computing capacity. Lambda should be within the free tier. Plus it scales automatically. The two functions are sized differently: the data collector runs at 1,024 MB because it builds pandas DataFrames from ~900 API responses in memory; the bot runs at 512 MB because its work is JSON parsing and S3 reads. Lambda billing is memory × duration, so sizing each function to its actual workload keeps costs low.
Decision · Storage
S3-based file storage over RDS or DynamoDB. RDS costs $20+/month minimum for an idle instance and adds VPC networking overhead. DynamoDB would require designing partition keys before knowing future analysis needs, and makes local data exploration harder. S3 costs ~$0.30/month, and I can download files for local analysis whenever I needed. The data access pattern is append-only writes and occasional full reads.
Decision · Credentials
Parameter Store over environment variables or Secrets Manager.
Parameter Store integrates natively with Lambda via IAM, includes KMS encryption,
and costs nothing for standard parameters. API keys are fetched at runtime by the Lambda function. The API keys were
never hardcoded, were never committed to git, and never saved in plaintext environment variables.
Secrets Manager would be the right choice if rotation were needed; for static API
keys, Parameter Store is the simpler and cheaper option. IAM access is scoped to
the /screener/* parameter path — not all of Parameter Store. S3 access
is scoped to the specific bucket ARN. The Telegram bot also performs application-level
authorization: each incoming message has its chat_id validated against
an authorized value stored in Parameter Store. Requests from unrecognized chat IDs
are rejected before any data is fetched.
Decision · Bot Trigger Model
Webhook mode over polling. In polling mode, a long-running process continuously calls Telegram's API asking for new messages — requiring always-on compute. In webhook mode, Telegram calls the API Gateway endpoint the moment a message arrives (what I type in Telegram), Lambda handles it and shuts down.
Decision · No VPC
Lambda in public mode, no VPC configuration. Lambda accesses S3 and Parameter Store through AWS internal service endpoints without a VPC. Adding a VPC would require a NAT Gateway (~$40/month) or VPC endpoints (~$7/service/month) for internet access. For this workload, VPC deployment adds cost and networking complexity without materially improving the security posture.
Where This Design Breaks Down
This architecture is well-suited to scheduled batch ingestion, low-frequency query traffic, and file-oriented analytics. It would stop being the right fit if:
- Query volume increased substantially — reading full CSVs on every bot request doesn't scale. A metadata index or DynamoDB layer for keyed lookups would be the next step.
- Latency became critical — cold Lambda starts and S3 reads add up. A warm cache layer would help.
- The data model grew more complex — CSV works well for flat tabular data. Parquet + Athena would be a better fit for larger datasets with ad hoc query needs.
- The
/triggercommand is fragile — it discovers the collector Lambda by scanning all functions in the account and matching the name of the Lambda function. Renaming the collector function would break the/triggersilently, with no error. The correct approach is to pass the collector's ARN as an environment variable at deploy time, making the dependency explicit.
What I'd Do Differently
-
Data validation and alerting. When the Polygon subscription lapsed,
the Lambda didn't fail — it logged "downloaded data for 0 stocks" and reported
success. The fix is two things: validate that the ingested data has today's date
before writing to S3, and publish a
stocks_analyzedmetric to CloudWatch on each run with an alarm that fires if the value drops to zero or the function hasn't run within the expected window. - Resource tagging from day one. Running multiple projects in one account without tagging makes cost attribution impossible. Each project should have been in its own account, or at minimum every resource tagged with a project identifier.
- S3 versioning strategy. Versioning was enabled without a lifecycle policy, causing exponential bucket growth as each daily CSV created a new version. A lifecycle policy to expire non-current versions after 1 day should have been configured at creation.