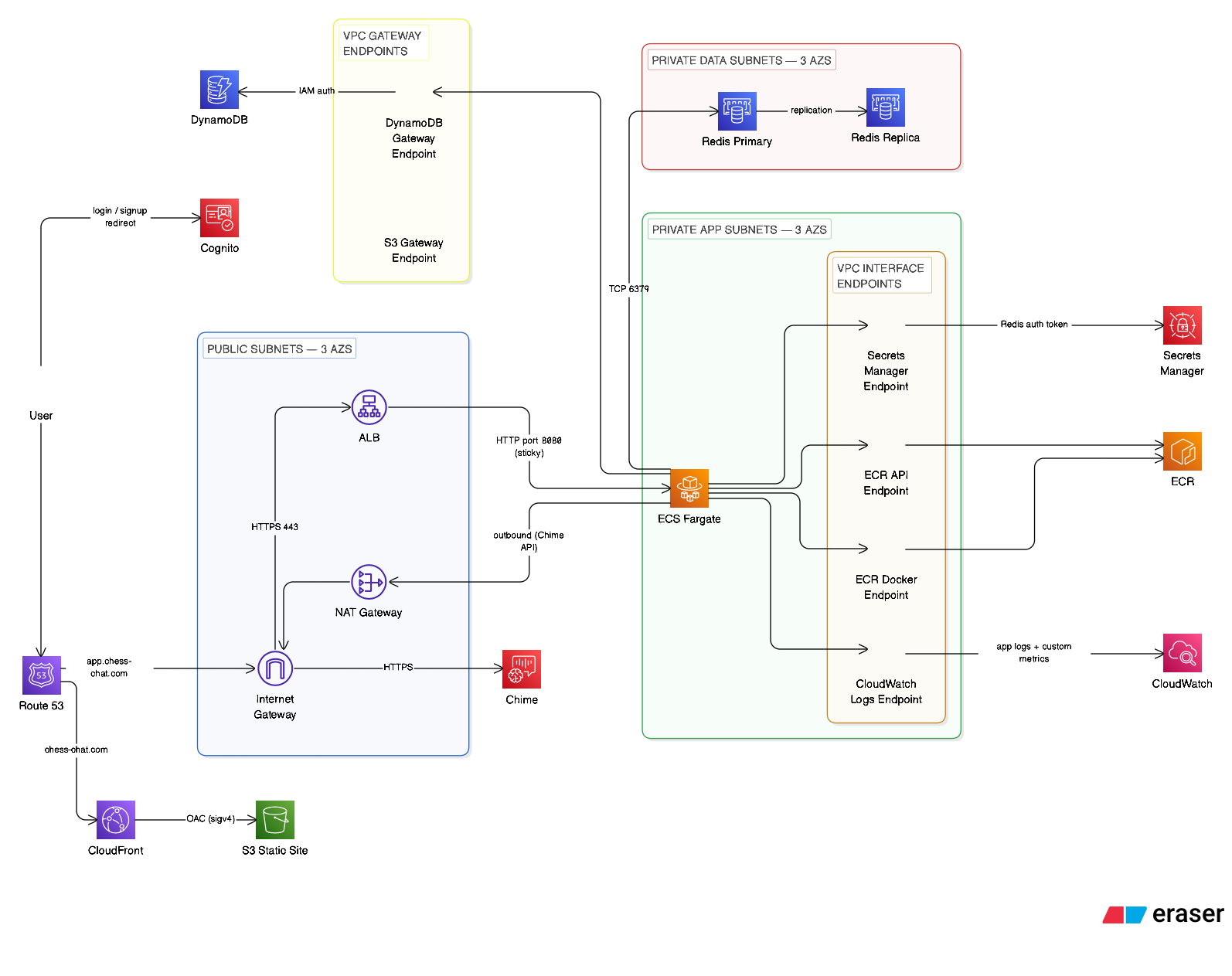
VPC Architecture
I built a three-tier VPC across three Availability Zones in
us-east-1 (CIDR 10.20.0.0/16). Each tier has a distinct
trust level enforced by both route tables and security groups.
| Tier | Subnets | Hosts | Internet |
|---|---|---|---|
| Public | 10.20.0.0/20, 10.20.16.0/20, 10.20.32.0/20 |
ALB, NAT Gateway | Inbound + outbound via IGW |
| Private App | 10.20.48.0/20, 10.20.64.0/20, 10.20.80.0/20 |
ECS Fargate tasks | Outbound only via NAT Gateway |
| Private Data | 10.20.96.0/20, 10.20.112.0/20, 10.20.128.0/20 |
ElastiCache Redis | None — no internet route |
The /20 subnets provide 4,094 IP addresses for each subnet (taking away the 5 addresses that AWS reserve). This is way more addresses than I will need, but there isn't really any downside in this isolated project. A tighter design would use smaller CIDR blocks based on the expected host count. In a shared enterprise VPC where IP address space is a shared resource, I would size my subnets accordingly.
Why Three Tiers?
It isolates my resources, which makes my application and infrastructure more secure. Security groups ensure only expected traffic is allowed at each layer. Route tables in the private tiers route 0.0.0.0/0 to a NAT Gateway rather than an Internet Gateway — NAT is outbound-only, so there is no inbound internet path to ECS tasks or Redis even if a security group rule were misconfigured.
NAT Gateway Strategy
A single NAT Gateway handles outbound internet from the private app subnets.
This introduces a single-AZ egress dependency. If I intended to design my infrastructure with more resilience, I would have a NAT gateway in each AZ.
The Terraform VPC module accepts nat_gateway_mode = "single" | "per_az"
so switching to per-AZ NAT requires one
small change.
Security Groups
Security groups enforce a strict one-directional trust chain. Each layer only accepts traffic from the layer directly above it.
Internet (0.0.0.0/0) │ 443 / 80 ▼ ALB Security Group │ 8080 (app container port) ▼ Fargate Task Security Group │ 6379 (Redis) ▼ Redis Security Group
The Redis rule references the Fargate task security group ID rather than a CIDR block. Since Fargate tasks are ephemeral and get random IPs, any new task automatically gets access just by being a member of that security group — no IP management needed as tasks scale.
VPC Endpoints
AWS API calls from Fargate tasks route through VPC Endpoints rather than the NAT Gateway. This eliminates NAT data processing charges on ECR image pulls, CloudWatch log writes, and Secrets Manager reads — and keeps traffic inside the AWS network.
| Endpoint | Type | Cost | Purpose |
|---|---|---|---|
| S3 | Gateway | Free | ECR image layer storage, static assets |
| DynamoDB | Gateway | Free | Database access from app tier |
| ECR API | Interface | ~$7/mo | Container image metadata |
| ECR Docker | Interface | ~$7/mo | Container image pull |
| CloudWatch Logs | Interface | ~$7/mo | Application log delivery |
| Secrets Manager | Interface | ~$7/mo | Redis auth token at task startup |
VPC endpoints could reduce NAT Gateway usage for AWS service traffic such as ECR pulls, CloudWatch Logs, Secrets Manager, S3, and DynamoDB. Gateway endpoints for S3 and DynamoDB are free, but other interface endpoints have their own hourly and per-GB costs — so whether they save money depends on AZ count, endpoint count, and actual traffic volume. More on this in my cost breakdown.
Terraform Structure
All infrastructure is defined in Terraform with a modular structure — one module
per AWS service boundary. The root main.tf wires modules together,
passing outputs as inputs (e.g. VPC subnet IDs feed into ECS and ElastiCache).
terraform/ ├── modules/ │ ├── vpc/ # VPC, subnets, IGW, NAT, route tables, endpoints │ ├── ecs/ # IAM task execution role and task role only │ ├── ecs_compute/ # ECS cluster, task definition, service, ECR repo, SG │ ├── alb/ # ALB, target groups, listeners, ACM cert │ ├── dynamodb/ # All DynamoDB tables and GSIs │ ├── elasticache/ # Redis replication group, subnet group, param group │ ├── cognito/ # User pool, app client, Google IdP │ ├── route53/ # Hosted zone, alias records, ACM validation │ ├── monitoring/ # CloudWatch alarms, dashboards, SNS, budgets │ ├── static_edge/ # S3 bucket + CloudFront for chess-chat.com apex │ └── github_actions_oidc/ # IAM OIDC provider + least-privilege deploy role ├── environments/dev/ │ └── terraform.tfvars ├── main.tf # Module wiring ├── backend.tf # S3 remote state config └── versions.tf # Provider version pins
ecs/)
creates IAM roles and policies only — task execution role and task role. The ECS compute module
(ecs_compute/) creates the cluster, task definition, ECS service, Fargate
security group, ECR repository, and CloudWatch log group. This split
breaks a circular dependency: the Redis security group needs to reference the Fargate
task security group as its source, but the task definition needs the Redis endpoint.
Separating the resources removes the cycle.
Module Outputs as Inputs
Modules expose typed outputs that other modules consume directly. For example:
# In main.tf
module "elasticache" {
source = "./modules/elasticache"
private_data_subnet_ids = module.vpc.private_data_subnet_ids
fargate_sg_id = module.ecs.fargate_task_sg_id
}
module "ecs_compute" {
source = "./modules/ecs_compute"
redis_endpoint = module.elasticache.primary_endpoint
redis_secret_arn = module.elasticache.auth_token_secret_arn
}
This wiring means Terraform's dependency graph is explicit — it knows to create ElastiCache before the ECS service, and to destroy the ECS service before ElastiCache.
Remote State
Terraform state is stored in S3 with versioning enabled and file-based locking
(use_lockfile = true). State versioning means any previous infrastructure
state can be restored from S3 version history if needed.
# backend.tf
terraform {
backend "s3" {
bucket = "chesschat-tfstate-xxxxxxxxxxxx-us-east-1"
key = "dev/terraform.tfstate"
region = "us-east-1"
use_lockfile = true
}
}
The state bucket name includes the AWS account ID to guarantee global uniqueness without a random suffix that would need to be tracked separately.
CI/CD Pipeline
GitHub Actions handles continuous deployment. Authentication to AWS uses OIDC (OpenID Connect). GitHub's OIDC provider is trusted by an IAM role, and the workflow assumes that role for the duration of the pipeline run.
Deploy pipeline steps on push to main (single job, sequential):
- Checkout source
- Configure AWS credentials via OIDC
- Login to Amazon ECR
- Build Docker image and push to ECR (commit SHA tag +
main-latesttag) - Generate
config.jsfrom GitHub Actions variables (Cognito IDs, app host, cookie config) and sync static auth assets to S3;config.jsis uploaded withCache-Control: no-storeso Cognito config changes are immediately live — all other assets use a 5-minute CDN cache - Trigger full CloudFront invalidation (
/*) - Register new ECS task definition revision
- Deploy ECS service and wait for stable state
- Upload deployment metadata artifact
Tests are not part of the deploy pipeline. Backend quality, frontend quality, and Terraform
quality checks run only in PR workflows and are enforced as required status checks on
main — branch protection is configured with enforce_admins = true
and required_conversation_resolution = true, with force-push and deletion disabled.
All of this branch protection configuration is managed as Infrastructure as Code using
Terraform's GitHub provider, so the repository settings are version-controlled and applied
consistently alongside the rest of the infrastructure.
Redis vs DynamoDB — The Split
The platform uses two data stores with deliberately separate responsibilities. The guiding principle: Redis holds what is needed right now; DynamoDB stores what needs to be remembered always. Active room metadata, in-progress game state, and the WebSocket connection map all live in Redis, they expire naturally when the session ends. Completed game records, user profiles and stats, and the friends connections live in DynamoDB.
Importantly, DynamoDB receives exactly one write per completed game, regardless of how many moves were played. All mid-game state lives in Redis. This keeps DynamoDB costs proportional to games completed, not game activity.
DynamoDB Schema
The schema uses a multi-table design — one table per domain — rather than a single-table pattern. IAM permissions, CloudWatch metrics, and PITR settings are all cleaner per-table. The social domain was also added after initial design; retrofitting single-table key namespacing would have been challenging, so this choice provided me with a level of freedom that I wouldn't have with a single table design. To stay as honest as possible, Claude helped design the schema based on my application requirements.
Users
total_games · wins · losses · draws · created_at · last_login_at
user_id as PK, not username?
Usernames can change. I wanted to implement a feature that utilsed chess.com OAuth integration, which would include a displacement mechanic
where a verified chess.com holder can claim a username held by an unverified user. However, this didn't eventuate.
Using an immutable Cognito sub means a username change is a single
UpdateItem, not a data migration.
Games
winner · result · total_moves · duration_seconds · room_code
time_white_remaining · time_black_remaining · moves[] · fen_history[] · pgn
Social Tables
Five additional tables support the social layer:
Friendships are written in both directions simultaneously (A→B and B→A), so listing
a user's friends is a single Query PK=user_id with no GSI required.
The Challenges table mirrors the two-GSI pattern from Games — a challenge involves
two parties and must be visible to both. The pair_rooms table stores a persistent
room code per friend pair: when a challenge is accepted, the backend derives a
deterministic pair_id (both user IDs sorted alphabetically and
concatenated) and looks up or creates the room code for that pair, so returning
friends always get the same room rather than a new random one each time.
Redis Schema
Redis stores ephemeral session state. All keys have a TTL and are treated as disposable — Redis state loss is survivable; DynamoDB loss is not.
room:{room_code} String (JSON-encoded), TTL 60min
{
status, waiting | active | teardown | terminal
chime_meeting_id,
chime_meeting_data,
participants, per-user connection state
active_game, null if no game running
games_played array of completed game summaries
}
ws:{connection_id} String (JSON-encoded), TTL 60min
{ user_id, room_code, connected_at }
room_expiries Sorted Set (ZSET)
member: room_code, score: expiry Unix timestamp
Background worker scans for expired rooms
room_reconnect_deadlines Sorted Set (ZSET)
member: room_code, score: reconnect grace deadline timestamp
Background worker scans for elapsed grace periods
game_finalization_queue List — jobs awaiting DynamoDB write
game_finalization_deadletter List — jobs that failed after 5 attempts
Room and connection state is stored as JSON strings using SET/GET,
not as Redis Hashes. WebSocket connection state lives in Redis (not in Fargate task memory)
so that any task can look up any connection — the foundation for distributed WebSocket routing
when the pub/sub relay is added.
The two sorted sets enable a background expiry worker to reliably scan for and act on expired rooms and elapsed reconnect grace periods, even when the originating WebSocket connection is gone. This is more robust than relying solely on Redis key TTL, which fires no callback on expiry.
The finalization queue is a Redis List used as a lightweight job queue: completed game data waits there until it can be written to DynamoDB. If DynamoDB is momentarily unavailable, the job sits in the queue rather than being lost. Jobs that fail five times are parked in the dead letter list for inspection rather than retried indefinitely.
Data Flow
Room Creation
- User A sends a challenge to User B → WebSocket message to Fargate
- Backend generates 8-char alphanumeric room code
- Room written to Redis with 60-minute TTL
- Room code returned to User A's browser
- User B enters code → backend validates room exists
- Backend creates Chime SDK meeting, generates attendee tokens for both
- Meeting credentials pushed to both clients via WebSocket
- Chime SDK initialises on both frontends — video active
Chess Move
- Player drags piece — chess.js validates move locally (UX speed)
- Move sent to backend via WebSocket:
{ move: "e2e4" } - Backend validates server-side with chess.js (authoritative source of truth)
- Board FEN, move list, and clocks updated in Redis
- Move broadcast to both clients:
move_madeevent includingmoveTypeandisCheckmetadata fields — the server drives the sound trigger type - Both frontends update board, clocks, and play the mapped sound cue
Game Completion
- End condition detected (checkmate / resignation / timeout)
- Game metadata calculated (duration, time remaining, move count)
- Finalization job pushed to Redis List (
game_finalization_queue) — write is decoupled from the in-flight WebSocket session to survive Fargate task crashes - Background worker pops the job and writes to DynamoDB as a conditional
PutItem(idempotent — safe to retry) - Failed writes retry with exponential backoff (base 250ms, up to 5 attempts); jobs failing all 5 attempts are pushed to
game_finalization_deadletter - User stats updated —
UpdateItemon Users table - Active game cleared from Redis room state
game_endedevent broadcast to both clients
Session Lifecycle
Room created (User A)
│ status: waiting
▼
User B joins
│ status: active — Chime meeting created
▼
Games played (unlimited sequential games)
│ Each game: Redis active_game → DynamoDB via finalization queue
▼
Player disconnects
│ 12-second reconnect grace (tracked in room_reconnect_deadlines ZSET)
│ Reconnect events carry a reconnectVersion — frontend ignores stale
│ updates with version ≤ last seen, preventing UI regression
│ If grace expires → teardown begins
▼
Both players leave (or grace expires)
│ Room transitioned to terminal: true via Redis WATCH/MULTI/EXEC (atomic)
│ New join attempts rejected once terminal
│ Chime meeting deleted
│ Active game (if any) queued for DynamoDB write
│ DEL room:{code} + ZREM from both sorted sets
▼
Room consumed — code is single-use
The terminal state transition is atomic (Redis optimistic locking via
WATCH/MULTI/EXEC). The subsequent cleanup — DEL and
removal from the two sorted sets — runs as separate commands after the transition
is confirmed. Single-use enforcement relies on the terminal state check: new join
attempts are rejected once the room is terminal, before the key is deleted.
WebSocket Routing
WebSocket connections require session affinity — a client must reach the same
Fargate task to maintain its connection. The ALB target group has sticky sessions
enabled (lb_cookie, 24-hour duration).
Connection state is stored in Redis (not task memory), so the foundation for distributed routing is already in place. Implementing the pub/sub relay is the remaining step.
Video Infrastructure
Current: Amazon Chime SDK
Chime SDK provides a managed WebRTC implementation. The server creates a meeting and issues attendee tokens; the client SDK handles negotiation, STUN/TURN, and media streams. Cost: $0.0017 per attendee-minute.
A 1-hour session with two players = 120 attendee-minutes = $0.20 per session.
Planned: Native WebRTC + Coturn
The migration replaces Chime SDK with browser-native WebRTC and a self-hosted Coturn TURN server. Cost becomes a flat EC2 instance fee rather than per-minute billing.
| Chime SDK | WebRTC + Coturn | |
|---|---|---|
| Cost model | $0.0017/attendee-min | Flat EC2 (~$15–30/mo) |
| Break-even | — | ~150 hours/month of video |
| Control | Managed (limited) | Full (codec, bitrate, signalling) |
| TURN required | Managed by Chime | Self-hosted (~15% of sessions) |
| SFU needed | No (1-on-1) | No (1-on-1) |
Migration sequence: keep Chime now → swap to WebRTC + single Coturn instance pre-launch → add redundancy post-launch → add regional instances based on user geography.
Security Model
| Control | Implementation |
|---|---|
| Network isolation | Three-tier VPC, private subnets for app and data planes |
| Least-privilege IAM | Separate task execution role (ECR/logs/secrets) and task role (DynamoDB/Redis/Chime) |
| Secrets management | Secrets Manager for Redis auth token and third-party API keys — never in env vars |
| TLS everywhere | ACM certificates on ALB and CloudFront, HTTP → HTTPS redirect enforced |
| Container security | ECR image scanning on push, lifecycle policy (retain last 10 images) |
| Encryption at rest | DynamoDB SSE (AWS-managed), Redis encryption at rest enabled |
| Auth | Cognito with email verification, password complexity, optional MFA |
| Audit | CloudTrail (all API calls), VPC Flow Logs, CloudWatch application logs |
| Static site isolation | S3 bucket private, CloudFront OAC — bucket accessible only from this distribution |
| Session cookie (v1) | JS-managed cross-subdomain cookie — accepted risk, HttpOnly migration planned (ADR-0003) |
IAM Role Separation
ECS uses two distinct IAM roles per task:
- Task Execution Role — used by the ECS agent to pull the container image from ECR, write logs to CloudWatch, and fetch secrets from Secrets Manager at startup. The application code never uses this role.
- Task Role — used by the application at runtime. Grants access to specific DynamoDB table ARNs, Chime SDK meeting operations, and ElastiCache describe operations. No wildcard resources.
Observability
Infrastructure Alarms
All alarms are CloudWatch Alarms, configured in Terraform's monitoring/
module and routed to an SNS topic for email notification. They cover the four
infrastructure components that could silently degrade the platform — compute,
load balancing, the database, and cost.
| Metric | Threshold | Window |
|---|---|---|
| ECS CPU utilisation | ≥ 75% | 1 × 5-min period |
| ECS memory utilisation | ≥ 80% | 1 × 5-min period |
| ALB 5xx errors | ≥ 5 in period | 1 × 5-min period |
| ALB unhealthy targets | > 0 | 2 × 5-min periods (10 min effective); treat_missing_data = breaching — catches scale-to-zero |
| ALB healthy hosts low | HealthyHostCount < 1 | treat_missing_data = breaching |
| DynamoDB throttled requests | Any | Warning |
| Redis CPU | ≥ 75% | 2 × 5-min periods |
| Monthly cost | 80% / 90% / 100% of $100 budget | Percentage alerts |
Application Metrics
8 custom metrics are emitted to CloudWatch in the Chesschat/Dev namespace
from the backend service (src/services/metrics.js):
WsConnectionsOpened/WsConnectionsClosedGamesStarted/GamesEndedGamePersistSucceeded/GamePersistRetried/GamePersistFailedAppErrors
These appear alongside infrastructure metrics on the CloudWatch operations dashboard.
The three GamePersist* metrics track the finalization worker's reliability
in real time — retries and dead-letters are immediately visible without log parsing.
Logging
Application logs are written to CloudWatch Logs (/ecs/chesschat/application)
with 30-day retention. VPC Flow Logs capture all network traffic in a separate log group
with the same retention.
Every HTTP request is assigned an x-correlation-id — either the
client-supplied value or a generated UUID — which is logged alongside method, path,
status, and latency. WebSocket sessions are traced the same way using a
sessionId and connectionId. When an alarm fires, the
correlation ID is the starting point: find the matching log entries and trace the
request end to end.
Cost Model
The March bill came to $212.25 (pre-tax) at near-zero actual usage. Almost the entire cost is fixed always-on infrastructure — the variable components (compute, data transfer, Chime) were negligible, whuhc makes sense as I was the onyl person using it.
| Service | March actual | Notes |
|---|---|---|
| VPC Interface Endpoints | $89.28 | 4 endpoints × 3 AZs = 12 endpoint-hours/hr — per-AZ pricing |
| NAT Gateway | $33.48 | Hourly charge only — 0.025 GB data processed |
| ElastiCache Redis | $23.81 | 1 primary + 1 replica, t4g.micro |
| ALB | $16.71 | Fixed hourly — negligible LCU usage |
| Domain registrar | $15.00 | Annual fee |
| Public IPv4 addresses | $14.85 | $0.005/hr per in-use address — AWS 2024 pricing change |
| ECS Fargate | $9.40 | 0.25 vCPU / 512 MiB baseline task |
| CloudWatch | $8.40 | 28 custom metrics at $0.30/metric |
| Other | $1.32 | Secrets Manager, Route 53, ECR, Chime ($0.03) |
| Total | $212.25 | Pre-tax |
The Always-On Problem
At this scale, the bill exposes a structural issue: roughly $163 of the $212 is fixed cost that runs regardless of whether anyone uses the platform. The NAT Gateway processed 0.025 GB of data but cost $33. The VPC endpoints processed 1.67 GB but cost $89. The ALB served negligible traffic but cost $17. This is the real cost of production-grade infrastructure running at development load.
The biggest surprise was the VPC Interface Endpoints. Interface endpoints are billed per-AZ — each endpoint deployed across three AZs counts as three hourly charges. Four endpoints across three AZs produces 12 endpoint-hours per clock hour, not 4. At low data volumes, this makes interface endpoints significantly more expensive than simply routing through NAT. The free Gateway endpoints (S3 and DynamoDB) are unaffected by this as they have no hourly charge.
At Scale, the Math Changes
The fixed costs stay flat while variable costs grow with usage. NAT data processing charges ($0.045/GB) and Fargate compute scale with real load — at meaningful traffic, the always-on baseline becomes a smaller fraction of total spend. The VPC endpoints also start paying for themselves: routing ECR pulls and CloudWatch log writes through endpoints rather than NAT avoids data processing charges that compound quickly at scale. The architecture is correctly sized for production; it is just expensive to run at near-zero load.
The WebRTC + Coturn migration eliminates Chime per-minute billing, replacing it with a flat EC2 instance cost — the right trade once session volume is predictable.